编译型语言和解释型语言:
- 编译:由编译器把整个源代码翻译成机器码,最终生成二进制文件,一次性提交给计算机执行。代表:C、C++
- 解释:由解释器将代码逐行解释成机器码,并交给计算机执行。代表:Python、JavaScript
第一个代码解读:
1 |
|
- #include
:这是一个预处理指令,告诉编译器需要使用一个叫做iostream的库 - std:是所谓的“命名空间”,为了避免还有别的cout对象重名起冲突
- :: :是作用域运算符,专门指明了用的cout是标准库std中的
- <<:是一个用来输出的运算符,它的使用规则是:左边需要一个“输出流”的对象,也就是输出到哪里;右边是要输出的内容
- endl:是一个“操作符”,表示结束一行,并把缓冲区的内容都刷到输出设备
- 注意:每个语句结束后,都要加“ ;”分号结束
1 | using namespace std; |
- 这句话的意思是使用标准命名空间 std,当加上这句话之后,就不要再写 std::
注释:
- 在C++中,有两种注释的表示。一种是单行注释,用双斜线 “//”,表示以它开始的当前行是注释内容;另一种是多行注释,使用一对“界定符”(/* 和 */),在它们之间的所有内容都是注释。
标识符:
不能使用C++关键字;
所谓的“关键字”,就是C++保留的一些单词,供语言本身的语法使用。包括:

以及C++中使用的一些运算操作符的替代名:

不能用连续两个下划线开头,也不能以下划线加大写字母开头,这些被C++保留给标准库使用;
函数体外的标识符,不能以下划线开头;
要尽量有实际意义(不要定义a、b,而要定义name、age);
变量名一般使用小写字母;
自定义类名一般以大写字母开头;
如果包含多个单词,一般用下划线分隔,或者将后面的单词首字母大写;
局部变量和全局变量:
- 局部变量:
- 在
函数体内定义的变量,也称内部变量。局部变量只能在定义它的函数中使用。
- 在
- 全局变量:
- 在
函数之外定义的变量称为外部变量,外部变量是全局变量(也称全程变量)。 - 一个程序中,凡是在全局变量之后定义的函数,都可以使用在其之前定义的全局变量。
- 在
- 当局部变量和全局变量同名的时候,采用就近原则
1 |
|
作用域:
- 全局变量:在本文件有效,不赋值的情况下,有默认值
- 局部变量:只在自己所在的大括号 {} 里面有效,在不赋值的情况下,不会有默认值
- 变量只有在其
作用域内才有效。出了作用域,变量不可以再被调用。 - 同一个作用域内,不能定义重名的变量。
- 注意:当变量出现重名,C++遵循就近原则
常量:
程序运行时,其值不能改变的量,即为
常量。字面常量:
- 2、12是整型常量,2.1、12.5、3.14是实型常量,’a’、 ‘b’、’c’是字符型常量
#define 定义的标识符常量:
在文件开头用 #define 来定义常量,也叫作“宏定义”。所谓宏定义,就是用一个标识符来表示一个常量值,如果在后面的代码中出现了该标识符,那么
编译时就全部替换成指定的常量值。即用宏体替换所有宏名,简称宏替换。定义格式:
#define 符号常量名 常量值符号常量名,称为
宏体,属于标识符,一般定义时用大写字母表示。常量值,称为
宏名,可以是数值常量,也可以是字符常量。习惯上,宏名用大写字母表示,以便于与变量区别。但也允许用小写字母。
1
2
3
4
5
6
7
int main() {
printf("zero = %d\n", ZERO);//结果输出0
return 0;
}
跟#include一样,“#”开头的语句都是“预处理语句”,在编译之前,预处理器会查找程序中所有的“ZERO”,并把它替换成0,这个过程称为预编译处理。
然后将预处理的结果和源程序一起再进行通常的编译处理,以得到目标代码 (OBJ文件)。
使用const限定符:
- 这种方式跟定义一个变量是一样的,只需要在变量的数据类型前再加上一个const关键字,这被称为“限定符”。
- 格式:const 数据类型 常量名 =常量值;
1
2
3
4
5
6
7
8
int main(){
//const 修饰的常变量
const float PI = 3.14f;
//PI = 5.14;//是不能直接修改的!
return 0;
}- const修饰的对象一旦创建就不能改变,所以必须初始化。
- 跟使用 #define定义宏常量相比,const定义的常量有详细的数据类型,而且会在
编译阶段进行安全检查,在运行时才完成替换,所以会更加安全和方便。
转义字符:

基本数据类型:
整型:
整型(integral type)本质上来讲就是表示整数的类型
在计算机中,所有数据都是以二进制“0” “1”来表示的,每个叫做一位(bit);计算机可寻址的内存最小单元是8位,也就是一个字节(Byte)。所以要访问的数据都是保存在内存的一个个字节里的。
C++定义的基本整型包括char、short、int、long,和C++ 11新增的long long类型,此外特殊的布尔类型bool本质上也是整型。

整型默认是可正可负的,如果我们只想表示正数和0,那么所能表示的范围就又会增大一倍。以16位的short为例,本来表示的范围是-32768 ~ 32767,如果不考虑负数,那么就可以表示0 ~ 65535。C++中,short、int、long、long long都有各自的“无符号”版本的类型,只要定义时在类型前加上unsigned就可以
由于类型太多,在实际应用中使用整型可以只考虑三个原则:
一般的整数计算,全部用int;
如果数值超过了int的表示范围,用long long;
确定数值不可能为负,用无符号类型(比如统计人数、销售额等);
char类型:
- char类型,通常只占一个字节(8位),char类型也可以进行整数计算,但它更重要的用途是表示字符(character)。
bool类型:
bool类型只有两个取值:true和false,通常占用8位(1个字节)
1
2
3bool bl = true;
cout << "bl = " << bl << endl;
cout << "bool类型长度为:" << sizeof bl << endl;true和false可以直接赋值给bool类型的变量,打印输出的时候,true就是1,false就是0
浮点类型:
- 浮点类型是用来表示小数,主要有单精度float和双精度double两种类型,double的长度不会小于float。通常,float会占用4个字节(32位),而double会占用8个字节(64位)。此外,C++还提供了一种扩展的高精度类型long double,一般会占12或16个字节。
- 在C++中,还提供了另外一种浮点数的表示法,那就是科学计数法,也叫作“E表示法”。比如:5.98E24表示5.98×1024;9.11e-31表示9.11×10-31。
- 一般来讲,float至少有6位有效数字,double至少有15位有效数字。所以浮点类型不仅能表示小数,还可以表示(绝对值)非常大的整数。
类型转换规则:
隐式类型转换:(自动类型转换)
- 系统自动将
字节宽度较小的类型转换为字节宽度较大的数据类型,它是由系统自动转换完成的
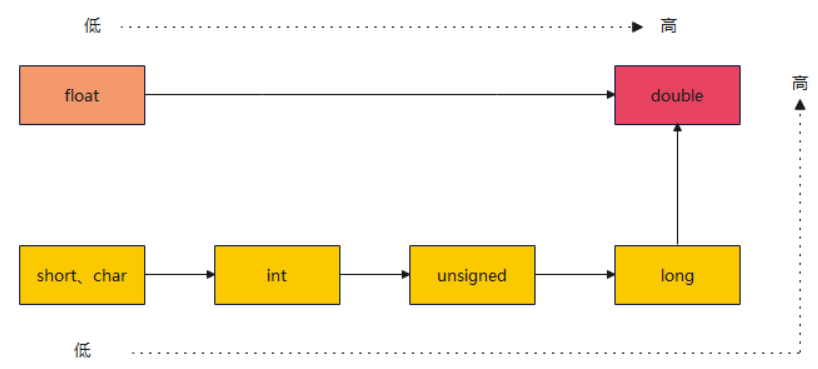
- **注意:**最好避免无符号整数与有符号整数的混合运算。因为这时 C 语言会自动将 signed int 转为unsigned int ,可能不会得到预期的结果。
- 系统自动将
显示类型转换:(强制类型转换)
- 形式: (类型名称)(变量、常量或表达式)
1
2double a=2.5;
int i=(int)a;- 功能:将“变量、常量或表达式”的运算结果强制转换为“类型名称”所表示的数据类型。
- 注意:强制类型转换会导致精度损失。
**注意:**无论是隐式类型转换,还是强制类型转换,都是为了本次执行程序的需要,并不会改变原来的类型和值
运算的溢出问题:每一种数据类型都有数值范围,如果存放的数值超出了这个范围(小于最小值或大于最大值),需要更多的二进制位存储,就会发生溢出。大于最大值,叫做**
向上溢出(overflow);小于最小值,叫做向下溢出**(underflow)。